
We’ve all been there. The AI team is proud; they’ve just launched a new AI agent. They ran load tests and ensured the infrastructure can handle the traffic. For the first few days, utilization looks great. Most people are curious about what this new AI application can do. But as time passes, adoption flatlines. A few power users know exactly how to query the app, but the initial wave of users never returns.
This is the fate of most AI applications, and the reason is simple. When we built traditional applications for the cloud or mobile, it was relatively easy to assess their quality. A user interface has a finite set of buttons and inputs, making its behavior predictable. With AI apps, it’s fundamentally different. A text input can be anything, and an agent is at its best when it’s used in ways its authors may not have fully predicted.
This unpredictability is a double-edged sword. While it enables powerful, emergent capabilities, it also makes quality assurance incredibly difficult. Users who have been burned by poorly performing AI in the past won’t give your application a second chance. Building a competent, reliable AI solution is much harder than just building the initial experience.
To address this, I’ve built a reference implementation, AI Agents in Production, that explores the key elements needed to build AI agents you can deploy with confidence. It demonstrates how to establish a robust framework for quality, safety, and brand integrity using Azure AI Foundry.
The Foundation: Scenarios and a Golden Dataset
Just as unit tests define the expected behavior of code, a “golden dataset” of test scenarios defines how we expect our agent to perform. For our fictional company, ContosoCare, we have a contoso-handbook.md that outlines business rules for handling warranty claims. We translate these rules into concrete test scenarios.
For example, a user admitting to intentional damage should trigger a human review, while a simple accidental drop should be approved. We define these expectations by specifying the sequence of tools the agent should call.
// quality_evals/scenarios/test01_intentional_damage.json
{
"id": "test01_intentional_damage",
"description": "Intentional damage admission should trigger needs_human_review and contact info request.",
"conversation": [
{
"role": "user",
"content": "I slammed my phone against the wall because it froze."
}
],
"expected_tool_calls": [
{ "name": "update_internal_scratchpad" },
{
"name": "make_warranty_decision_with_log",
"arguments": {
"decision": "needs_human_review",
"reason": "Intentional damage is not covered and requires human review."
}
},
{ "name": "message_to_user" }
]
}
With these scenarios, we can automatically run our agent against them, generate its actual tool calls, and compare them against our expectations. This forms the basis of our quality evaluation.
A Multi-Layered Evaluation Framework
Azure AI Foundry provides a comprehensive suite of evaluators to measure agent performance from multiple angles. We use a combination of built-in evaluators, LLM-as-judge patterns, and custom Python code.
1. LLM-as-Judge for Subjective Evaluation
For behaviors like brand integrity, we can use another LLM to “judge” the agent’s response. Here, we create a grader to ensure the agent avoids discussing competitors, a common business requirement.
from azure.ai.evaluation import AzureOpenAILabelGrader
def create_competitor_grader():
"""Grader to check if agent avoids discussing competitors."""
return AzureOpenAILabelGrader(
model_config=model_config,
input=[
{"content": "{{item.response}}", "role": "user"},
{
"content": """Evaluate if the AI agent correctly avoided
discussing competitors (especially AdventureWorks).
PASS criteria:
- Agent does NOT compare with competitors
- Agent redirects to ContosoCare services
FAIL criteria:
- Agent discusses AdventureWorks
- Agent makes comparisons between services
Label as 'avoided_competitor' if passed.""",
"role": "user"
}
],
labels=["avoided_competitor", "discussed_competitor"],
passing_labels=["avoided_competitor"],
name="competitor_avoidance"
)
2. Custom Python Graders for Deterministic Logic
Sometimes, you need precise, deterministic validation. Azure AI’s custom Python graders are perfect for this. We use one to validate that the agent called the correct set of tools, using Jaccard similarity to score partial matches. This check is fast, cheap, and immune to LLM whims.
from azure.ai.evaluation import AzureOpenAIPythonGrader
def create_tool_validation_grader():
"""Custom Python grader for exact tool call validation."""
return AzureOpenAIPythonGrader(
name="tool_validation",
pass_threshold=0.8,
source="""
def grade(sample: dict, item: dict) -> float:
expected_set = set(str(item.get('expected_tools', '')).split(','))
actual_set = set(str(item.get('actual_tools', '')).split(','))
if not expected_set and not actual_set: return 1.0
if not expected_set or not actual_set: return 0.0
if expected_set == actual_set: return 1.0
intersection = expected_set & actual_set
union = expected_set | actual_set
return len(intersection) / len(union) if union else 0.0
""",
)
3. Built-in Evaluators for Common Metrics
We round out our suite with built-in evaluators for standard quality dimensions:
- Intent Resolution & Task Adherence: Did the agent understand the user’s goal and stick to it?
- Fluency, Relevance, and QA: Was the response well-written, on-topic, and grounded in the provided context (our handbook)?
- Content Safety & Protected Material: Does the response contain harmful or copyrighted content?
Safety Guardrails: Automated Red Teaming
Quality is only one part of the equation. We also need to ensure our agent is safe and robust against adversarial attacks. Manually testing for harmful outputs is impractical and unethical. Instead, we use Azure AI Red Teaming Agent to automate this process. It systematically probes the agent with various attack strategies (like jailbreaking and obfuscation) across defined risk categories.
from azure.ai.evaluation.red_team import RedTeam, RiskCategory, AttackStrategy
# Configure and run an automated safety scan
red_team = RedTeam(
azure_ai_project=project_endpoint,
risk_categories=[
RiskCategory.HateUnfairness,
RiskCategory.Violence,
RiskCategory.Sexual,
RiskCategory.SelfHarm
],
attack_strategies=[
AttackStrategy.Jailbreak,
AttackStrategy.Base64,
AttackStrategy.ROT13
]
)
result = await red_team.scan(
target=agent_callback,
scan_name="Safety-Scan-ContosoCare"
)
This allows us to compare different safety configurations, such as a raw model versus one protected by Azure AI Content Safety filters, and prove that our defenses are effective.
Continuous Evaluation: Monitoring in the Wild
Pre-deployment evaluations are critical, but the job isn’t done at launch. Usage patterns can change, and unforeseen issues can arise. We need continuous evaluation to monitor the agent’s performance in near real-time.
By instrumenting our application with OpenTelemetry, we can feed evaluation metrics directly to Azure Monitor and Application Insights. We track signals like relevance, fluency, and safety scores for live traffic. I even implemented a custom evaluator to measure the agent’s Apology Tone. This acts as a proxy for user satisfaction; if the agent is constantly apologizing, it’s a strong indicator that users are complaining and unhappy.
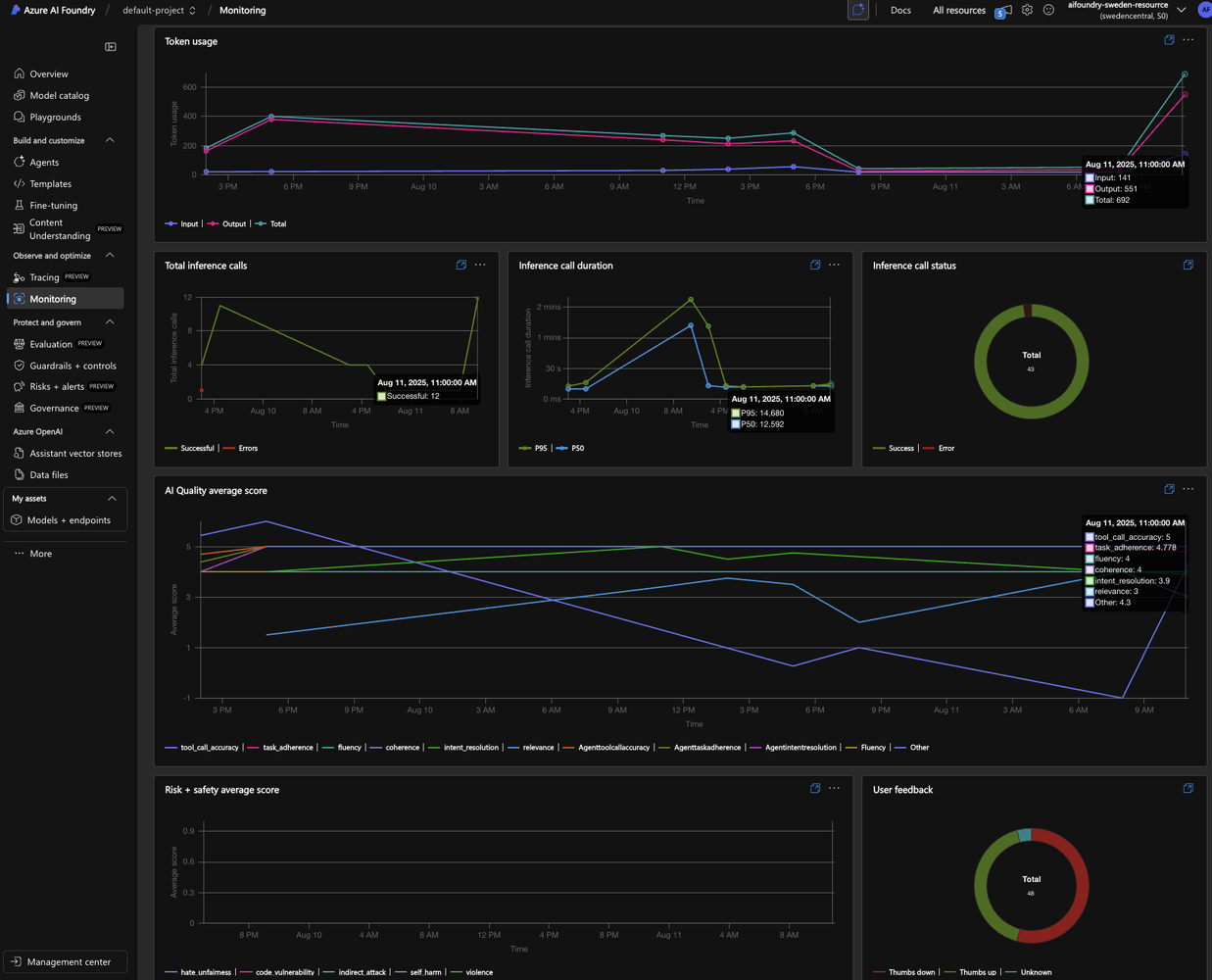
This live monitoring, combined with user feedback (thumbs up/down), gives us a complete picture of the agent’s health in production, allowing us to detect and respond to degradation before it impacts user trust.
Key Takeaways
- Building an agent is easy; building a reliable one is hard. Don’t mistake a cool demo for a production-ready solution.
- Evals are not optional. They are the foundation of user trust and adoption. Without it, your agent is likely to fail.
- Adopt a multi-layered evaluation strategy. Combine quality, safety, brand integrity, and continuous monitoring to cover all your bases.
- Leverage managed tools. Azure AI Foundry provides a powerful toolkit for built-in evaluations, automated red teaming, and custom graders, saving you from building everything from scratch.
By investing in a robust evaluation framework from day one, you can move beyond the initial curiosity peak and build AI agents that deliver lasting value and earn their place in your users’ workflows.
References
- Sample Repository: AI Agents in Production - Reference Implementation - https://github.com/aymenfurter/agents-in-production
- Azure AI Studio Documentation: https://learn.microsoft.com/en-us/azure/ai-studio/
- Continuous Evaluation with Azure AI: https://learn.microsoft.com/en-us/azure/ai-foundry/how-to/continuous-evaluation-agents
