In the initial wave of AI adoption, the focus was on making unstructured data discoverable. We used techniques like chunking and vector search to find the relevant parts of documents to answer a question, then provided that as context to the model.
What I’ve seen since are more complex use cases: giving agents not only access to knowledge but also the capability to execute actions. A great example is the ability to run SQL queries, allowing LLMs to tap into structured data, not just unstructured content. While this is a popular use case in hackathons and demos, I’ve seen these kinds of projects often get stuck in PoC land, unlike standard RAG implementations. Getting most queries right is surprisingly simple, but Text-to-SQL solutions can be sneaky, and incorrect answers don’t always throw errors.
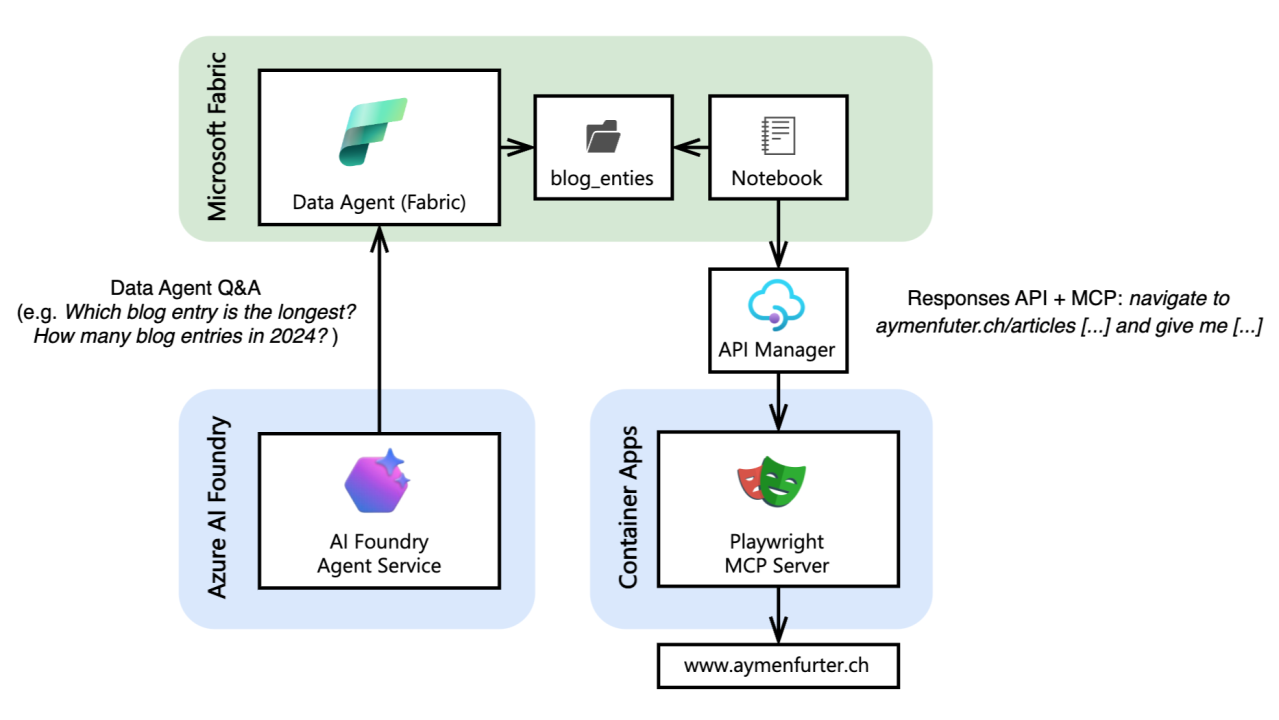
Microsoft Fabric’s Data Agent is an option that allows you to offload this complexity. Once your data is transformed and available in Fabric, you create a new data agent via the UI. Additionally, you can include sample queries and instructions for the agent to better understand the data and correctly write queries. That’s it. Once published, it’s accessible through Copilot Studio and Azure AI Agent Service. Integrating Fabric’s data agent into an agent is simple: just add the FabricTool via the Azure AI Foundry SDK. The best part is that the identity of the user calling the agent service gets propagated, so users only have access to the data they have permission to within Fabric.
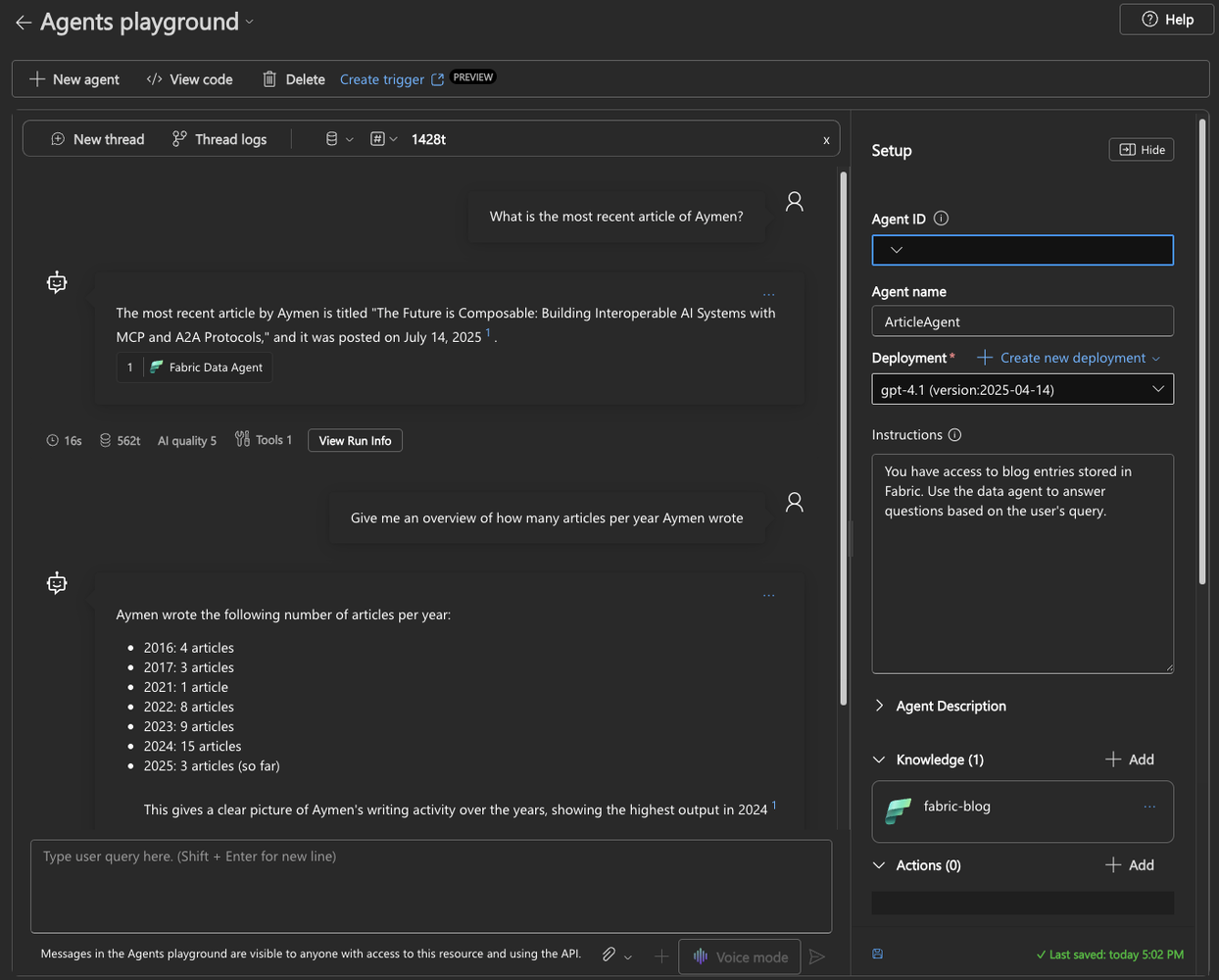
Azure AI Agent Service connected to Fabric’s Data Agent
To make the example realistic, we will use actual data. In this case, I decided to crawl my own blog. Large Language Models (LLMs) cannot access the web by themselves, so we need to provide them with a way to browse. The simplest way is to give the LLM a browser it can control. We do this by running a Playwright MCP server, which exposes a browser through the Model Context Protocol. This MCP server can be containerized and deployed on Azure Container Apps.
The entire setup script for this is in the project repository. Once running, the MCP server acts as a bridge: the LLM sends instructions to the MCP tool, which then uses Playwright to navigate pages and return structured data.
First, we define the expected output of the crawling process using Pydantic. In this example, the goal is for the LLM to return a list of blog URLs from aymenfurter.ch/articles:
class BlogUrlResult(BaseModel):
blog_urls: List[str] = Field(..., description="List of blog post URLs extracted from the page")
# ...
Next, we configure the MCP tool for the LLM to use. This involves adding security with an Azure API Management subscription key, so only authorized requests can reach our MCP server.
mcp_tool = {
"type": "mcp",
"server_label": "mcp-server",
"server_url": MCP_SERVER_URL,
"headers": {"Ocp-Apim-Subscription-Key": MCP_SUBSCRIPTION_KEY},
"require_approval": "never"
}
Then, we call the Responses API with a simple prompt. Notice that we specify the expected output format using the text_format parameter, which is set to our BlogUrlResult model. This instructs the API to parse the model’s output into a strongly typed structure instead of plain text, making the response predictable and easy to work with.
def extract_blog_urls():
prompt = "Navigate to: https://aymenfurter.ch/articles/ and extract all blog post URLs."
print("STEP 1: Extracting blog URLs")
return client.responses.parse(
model=AZURE_OPENAI_DEPLOYMENT,
input=[
{"role": "system", "content": "You are a scraper that extracts blog post URLs from a webpage."},
{"role": "user", "content": prompt}
],
tools=[mcp_tool],
text_format=BlogUrlResult
).output_parsed
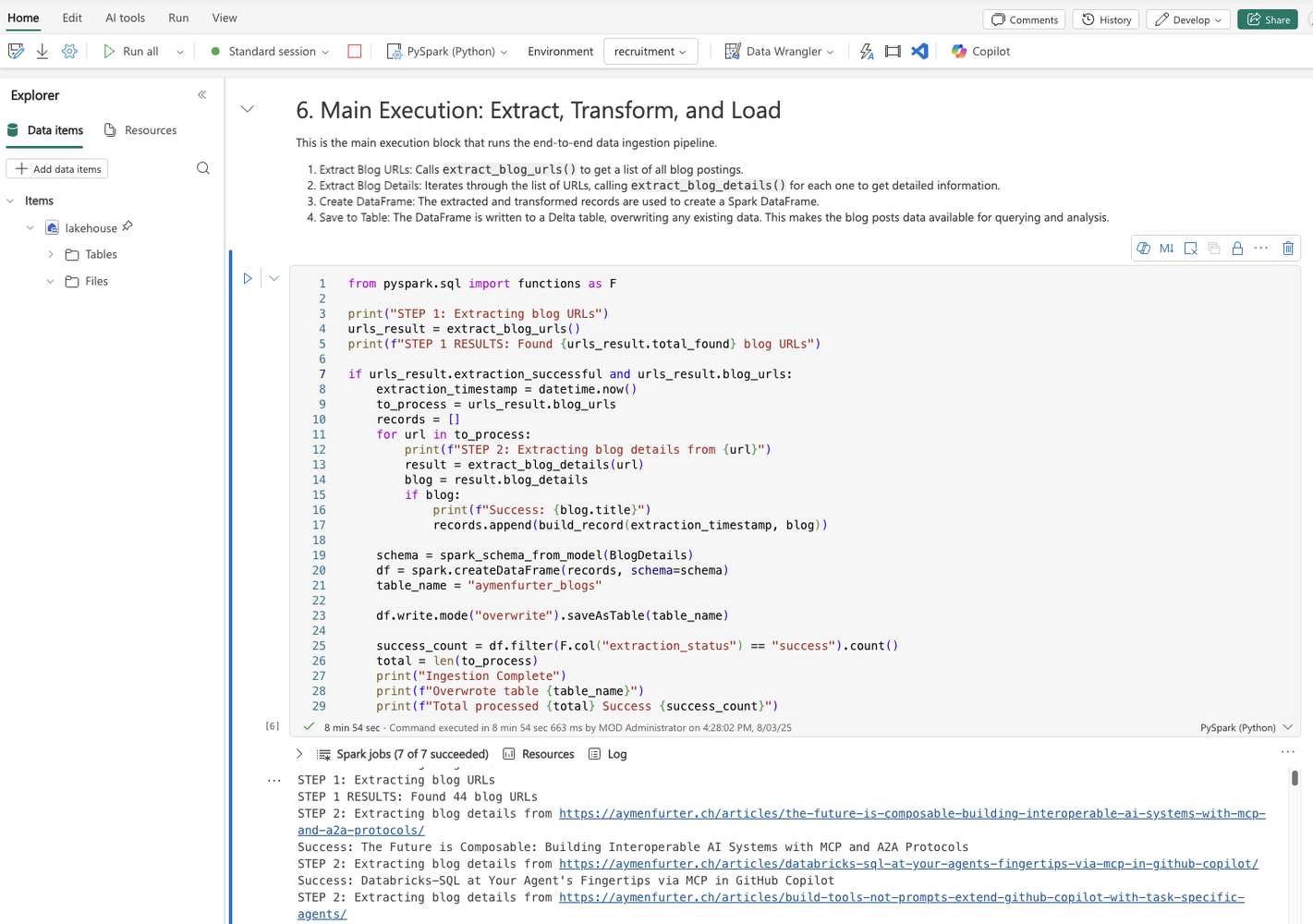
To persist this data, we can use PySpark and run this process directly within a Fabric Notebook, which saves the data into the Lakehouse:
For building and deploying the actual pro-code app that talks to the agent service, I recommend taking a look at this repository by Ali Asgar Juzer. It shows not only how to set up the agent via Python but also showcases how to set up Entra ID login and token propagation.
Key takeaways
Before building a full NL2SQL solution yourself, take a look at a managed Data Analytics Platform like Microsoft Fabric. It solves not only the NL2SQL challenge through its Data Agent but also provides Lakehouse storage, data integration pipelines, and Power BI integration.
By ingesting the data first into Fabric, then using AI Agent Service to query it, we get secure, governed access to structured insights with minimal code and integration into the Microsoft ecosystem. We also showed how to use an agentic crawler pattern with Playwright and OpenAI’s Responses API, giving an agent browsing capabilities to extract real-world data before storing and processing it in Fabric.
References
- Sample Repository: Notebook Code & Playwright MCP + APIM Deployment - https://github.com/aymenfurter/agentic-crawler/
- Sample Repository: Fabric Data Agent Pro-Code Deployment (by Ali Asgar Juzer) - https://github.com/aliasgarjh/fabric-data-agent-chat
- Azure OpenAI Responses API (Preview): Official documentation - https://learn.microsoft.com/en-us/azure/ai-foundry/openai/how-to/responses
- Creating a Fabric Data Agent (Preview): Microsoft Fabric documentation - https://learn.microsoft.com/en-us/fabric/data-science/how-to-create-data-agent
